Application Support in Docker-based Microservice Environments
How to provide essential services with minimal application involvement.

Introduction
Operationalizing microservices is difficult and that difficulty has been exacerbated by how much the landscape has changed over the last 5 years. Personally, I've worked on a few microservice architectures and experienced the evolution of thoughts, patterns, and technologies that have brought us to where we are today. Needless to say, it's overwhelming. The practices we followed 5 years ago seem antiquated by today's standards.
More importantly, there is a vast difference between reading about these technologies on blogs or books and maintaining them in production. My goal is to impart some of the lessons I've learned in hopes that you will not make similar mistakes.
This article is the first in a compendium related to supporting microservices. Future articles will discuss and provide examples of using technologies to provide essential support services in the areas of:
- Logging and Exception Reporting
- Configuration
- Service Discovery
- Metrics and Alerting
I will link to the articles as they are published.
However, in this first article, I would like to discuss the general patterns and anti-patterns of providing crosscutting functionality to microservices. By crosscutting, I mean the common platform features needed to manage and maintain applications in a microservice environment. We will start by discussing why applications need support services to be operationalized.
No Service is an Island
The term microservices is somewhat of a misnomer. What we really mean is that the scope of domain logic handled by a service is micro, but that service still has the typical responsibilities of an application living in a production environment.
For instance, it's essential to know when a service dies or experiences an error. We also need to know about the load on an application to determine its health. We probably also want to know things from a business standpoint. How many users did we see today? How many are new signups? How long did they stay on our site?
On the other hand, services often need things from the environment. For instance, a service may need to know the S3 bucket it's supposed to upload images to. Perhaps it knows the location but needs AWS credentials to perform the upload.
These examples demonstrate the "connected" nature of a microservice to its environment and other services:
Services have operational responsibilities: Services need to log their activities, report exceptional or significant conditions, and provide metrics -- all of this on top of its basic business domain responsibilities.
Services have dependencies on other services: A service, particularly when operating as a microservice, is unlikely to be unaware of other applications in the environment. In fact, it's more common than not to have an application consuming the APIs and events of other microservices.
Services have dependencies on the platform: Services will need to configure themselves for their deployed environment, which means they will need some mechanism for retrieving configuration and credentials from the platform.
Application Support in the Era of Docker
The way that we used to support applications is no longer valid in highly dynamic container environments. We can no longer assume we know where are applications are deployed, nor should we continue to allow them to participate so actively in our infrastructure. Let's take some time to consider why these strategies have become antipatterns.
Don't assume the location of a container
We used to know where our applications were deployed, which allowed us to create support mechanisms tailored to those hosts. This might include dedicated log aggregation and rotation targeting a specific directory on a host or using a provisioner to update configuration files. Service discovery was even simpler - we knew the IP or Hostname of the service and the exposed port.
Docker-based microservice architectures have made supporting applications significantly more difficult than the days of deployments to known hosts. Container schedulers make the location of applications relatively unpredictable, particularly in large environments. An application can be placed on hosts based on available resources, reliability (e.g. spreading across availability zones), or opportunity (spare CPU cycles). We also cannot assume we know when a container will be moved or terminated due to failures of the application, failure of the host, and draining or upgrade events.
This brings us to the first principle:
Do not provide supporting services assuming you will know a container's location.

Schedulers make container placement unpredictable, which is why you should not provide services assuming you know where the application will be.
Many schedulers will allow you to do the wrong thing. For example, Amazon ECS will allow you to define placement constraints allowing a container to target a specific EC2 instance. Think about the consequences of using this strategy:
- Best-case scenario: a controlled termination of the host will require you to first create a new ECS instance with the supporting services required by that application. Then you will need to update the ECS Service/Task to deploy to the new server.
- Worst-case scenario: the EC2 host is terminated unexpectedly. ECS, finding no EC2 host meeting the container's requirements, is unable to place the container somewhere else in the environment.
Which leads to my next major piece of advice:
Do not circumvent transient container placement in your environment.
Instead, learn how to provide application support in a transient environment. This will make your infrastructure significantly more resilient allowing it to scale and recover from errors gracefully.
Minimize your application's awareness of supporting services
Application developers often make the mistake of integrating support services directly into applications. The most common example of this is logging. We often employ complex, multi-target logging clients to transform, filter, and send events to multiple outputs: console, file system, remote aggregator (Logstash or Fluentd), or SaaS product (Loggly, LogEntries).
Consider what this does to your application. A portion of the application's CPU and memory allocation is dedicated to transforming and routing logs to various destinations -- a cost not insignificant to the application's overall performance. More importantly, it's unlikely we will want to support the same sort of logging scenario in every environment (e.g. development, QA, production). To ensure we aren't utilizing expensive SaaS services, or flooding our production log store with development events, we must now complicate the application further by supporting radically different configurations for each environment.
Instead, what if the environment determined how logging should work? Meaning, what if the application was only responsible for outputting structured messages to stdout and stderr and the environment transformed and delivered the events to the appropriate location? You wouldn't need to change configuration between environments, mock or provide endpoints in development, or slow down the application with an unnecessary concern.
This principle is very common in microservice environments powered by Docker. For instance, Docker itself provides the mechanism for aggregating stdout and stderr output via Logging Drivers. This is true of other monitoring components. Instead of directly reporting metrics to Statsd or InfluxDB, you can expose application metrics as an HTTP endpoint and allow services like Telegraf or Prometheus to collect them on their own schedule.
In microservices environments, it is essential to invert the relationship between the application and supporting services, allowing supporting services to command or query the application, not the other way around.

Inverting the application's dependencies dramatically simplifies the application. In the diagram above, we were able to remove four remote service dependencies by introducing support containers. Of course, the platform is definitely more complicated, though I would argue the complexity is worth the cost. We will cover these individual technologies in future articles.
Now that we have a better understanding of why we want to make services unaware of their environment, let's discuss how we dynamically support containers when we can't predict where they will be deployed.
Patterns of Service Integration
There are various patterns we use to connect applications to support services. I would personally organize these patterns into four general categories:
- Remote Services
- Host Services
- Container Sidecars
- Network Abstractions
Remote Services
Remote services are the category developers are most familiar with. By remote service, I simply mean a process accessible over the network that provides some sort of support to the application. This might be a database or another microservice, but it could also be a support service like a log aggregator, configuration service (like Consul), metrics backend, etc.
While I generally recommend using remote services as little as possible, sometimes it's impossible to get away from the practice. For instance, you may need to access a database and choose not to run a proxy on the local host. This is also a common pattern for accessing SaaS services, particularly internal ones within your cloud provider (like Amazon RDS, ElasticCache, or SQS).
The important thing to remember about this pattern is that it is best not to hardcode the IP address, hostname, or port of the service. This typically leaves two options:
- Find the location of the service through dynamic configuration (environment variable or a configuration template rendered by a Sidecar service -- more on this in a minute).
- Utilize DNS to transparently discover the service location. Consul exposes a DNS interface that you can configure Docker containers to use. If you support multiple environments with your Consul cluster, prefix the service you want to communicate with using the environment name:
{environment}.mongodb.service.us-west-2.consul.
There is a third option where a remote support service can discover the location of the application and collect data from that service (Prometheus does this). This pattern is not common since it requires a support service to know how to discover services in your architecture.

The diagram above demonstrates a sidecar deployment of Consul Template providing that will render configuration files for the application using data in Consul. Consul can also be used as a DNS provider allowing the application to locate the remote resource.
The use of remote services implies the application knows where those services are located within the architecture. An alternative is to remove the discovery process altogether and allow applications to assume the location of a support service is always on the local host. We refer to this approach as "host services".
Host Services
Some services are so common across applications that it makes sense to provide them at the host-level (meaning each server/VM has a singleton instance of that service). This category has three general patterns:
Assumed Availability on Host
A singleton service exposes an API accessible to transient containers deployed on the host. For instance, applications that need dynamic configuration or service discovery may choose to access the Consul agent directly (instead of passively using DNS or Consul Template for configuration).
Keep in mind, however, that you will not be able to make calls to localhost to access host services unless you use host networking in Docker. If you use bridge networking, you can still access the host it's just a little more complicated.
For more information about accessing host ports from a bridge, refer to this Stack Overflow thread: https://stackoverflow.com/questions/31324981/how-to-access-host-port-from-docker-container
Docker Daemon Integration
Many services integrate transparently with transient containers using the Docker daemon. For instance, Logspout uses the Docker daemon to consume stdout and stderr from containers and forward that data to an endpoint like Logstash. Another fantastic library, Registrator, watches the Docker daemon for container registration and removal events and forwards that knowledge to Consul for the purpose of service discovery.
Antipattern - Host service watches a volume shared with a container
Another way to integrate with transient containers is to have a support service monitor shared host volumes used by applications. A contrived example might be a process deployed to the host designed to backup a Jenkin's workspace. Perhaps that process executes a task at midnight to archive the directory and push the result to S3.
I consider this an antipattern because it's hard to predict when the support service will be useful. For instance, what if there are no Jenkins containers deployed to the host? Should the support service just remain idle, occasionally wasting CPU cycles checking to see if Jenkins magically appeared and wrote its workspace to disk? More importantly, do we really want that process deployed to every Docker host in our cluster when we will only have one instance of Jenkins deployed at a time?
In my opinion, a better pattern for deploying support services tailored to a single container is the container sidecar pattern. We will discuss this approach in the next section.

Examples of providing support to an application container from the host. The application communicates to the local Consul Agent using the Consul API (HTTP :8500). We also have an example of Docker integration with Registrator. For completeness, I've also added an example of the antipattern.
Container Sidecars
The sidecar pattern involves deploying support containers alongside the primary application container. The term comes from the motorcycle sidecar, a compartment you can attach to the vehicle to allow a passenger to ride comfortably:

The sidecar pattern requires a container scheduler that allows multiple containers to be deployed as a single unit. The implementation is usually specific to that technology. For instance, AWS ECS allows multiple containers to be defined in a Task Definition. In Kubernetes, sidecars are containers defined in the same Pod as the primary application.
Sidecars typically offer capabilities in two ways:
Shared Volume
The sidecar shares a volume with the primary container and performs things like data backups, file synchronization, refreshing configuration files, etc. Consul Template is a perfect example of a shared volume sidecar. Consul Template watches for changes in KV data or service registrations in Consul and uses that data to render a file within the shared volume. Consul Template can also execute a command after a template is rendered (typically a command that restarts the primary container, thereby refreshing the application's configuration).
Assumed Availability within Deployment
Another use of sidecar is to provide a service accessible to the application container via the bridged network between containers or the old Docker link mechanism. In this way, the application container can always refer to the sidecar container by name knowing it will be available by virtue of being co-deployed with the app. The quintessential example of this style of the sidecar pattern is Buoyant's Conduit proxy. Conduit is a lightweight service mesh entry point for Kubernetes environments which helps form a service mesh network abstraction for applications (see next category).

Containers inside the gray box are assumed to be in the same deployment (ECS Task or Kubernetes Pod). In this example, Consul Template is reading data from Consul and rendering the application's configuration. Consul Template might also send a SIGHUP signal to the application letting it know it needs to reload its configuration.
The example also demonstrates the use of "Assumed Availability within Deployment" with the use of Conduit. When the application wants to communicate with another application, it will communicate with Conduit instead of the service directly.
Network Abstractions
A more recent pattern of service integration is to create a virtual network in which applications communicate with and receive requests from an isolated set of related containers. This practice is quickly becoming the preferred model for connecting services because it hides service discovery from applications, and in the case of mesh networking, can offer additional benefits like advanced routing (load balancing, connection siphoning, and failover) transparently to clients.
There are two general types of network abstractions used in Docker environments:
Overlay Networks
An overlay network is a virtual network built on top of an existing network (physical or virtual). In Docker, this means that we can create a virtual network between a set of containers where they can communicate using well-known hostnames or IP addresses but are isolated from the other containers in the platform, as well as, services operating within lower networks (a better discussion can be found here: http://blog.cimicorp.com/?p=2649). Overlay networks simplify networking between containers and can remove the need for service discovery since all containers in the overlay network are addressable by a simple hostname. More importantly, the network prevents containers from accessing the wrong instance of a service (e.g. QA accessing production) due to the inherent isolation of the network.

Docker daemons construct the overlay network for a single deployment. The mechanism for the network isolation depends on the scheduler technology.
When we talk about overlay networks in Docker, we are actually referring to what CimiCorp calls a "Nodal Overlay Network". This means the network is managed by special nodes responsible for forming the virtual network layer.
Another type of overlay network is the "Mesh Overlay Network", more popularly referred to as a"Mesh Network".
Mesh Networks
Mesh networks are built from container components instead of the Docker host (Nodal Overlay) and are generally more popular in Docker because of the advanced features they provide. Mesh networks typically involve a service located on the host or deployed as sidecar that serves as a bridge for applications to communicate over the network.
The topology of the network is typically defined by another service, which propagates routing information to the proxy nodes that serve as the gateway. The "topology service" has the responsibility of knowing where all services are within the mesh, as well as, maintaining routing rules on how to transfer requests between services on that mesh. There are various ways in which this is done, but generally, it involves an existing service discovery solution (Consul, Kubernetes API) and a database that contains routing rules.
While it's not an inherent capability of mesh networks, most implementations offer features to trace, load balance and transform requests. Mesh networks are also generally capable of adapting the network to remove nodes repeatedly experiencing communication failures.
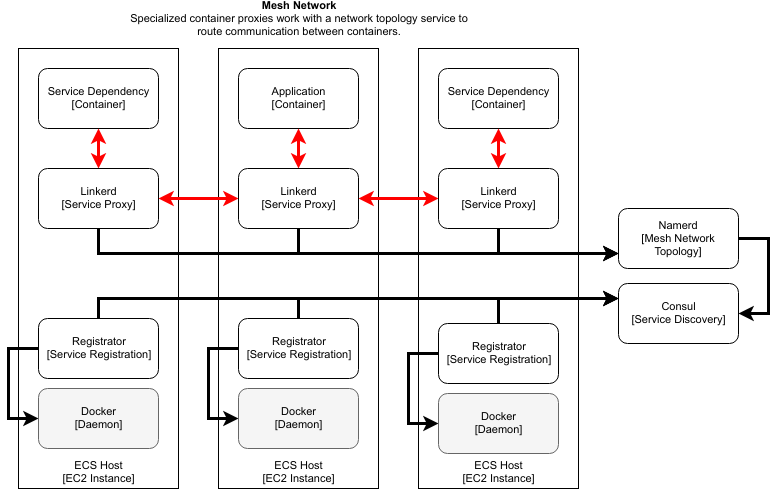
This is a typical setup for a Linkerd mesh network. Registrator watches container registrations in Docker and reports those services to Consul. When a service communicates over Linkerd, Linkerd will look up routing information in Namerd. Namerd will apply its set of routing rules, which generally end in a dynamic service lookup against Consul. Linkerd will then pass the message to the resolved service.
We will discuss mesh networks in detail in a later article, including the use of Linkerd, a fantastic mesh networking solution I have used in the past.
Ambassador Containers (Obsolete)
I wanted to briefly mention an older network abstraction called the Ambassador Container pattern. The pattern is basically the use of a container as a local proxy to a remote service. When transient service containers are deployed to the host, they can use the notion of Assumed Availability on Host to connect to the Ambassador container, thereby, connecting to the remote resource.

This pattern was declared "obsolete" by Docker. The problem with Ambassador Containers is that in order to make it work, you will have to adopt an antipattern. Since we can't assume we know where a transient container will deploy, we are left with a few courses of action:
- Deploy the Ambassador Container to every host and use "Assumed Availability on Host". However, hosts might not have any services needing the Ambassador. Therefore, this pattern is a waste of resources.
- Deploy the Ambassador Container as a sidecar, but have it determine where to connect to the remote resource. The problem with this strategy is that the whole premise of having an Ambassador Container is negated. Why not passively configure the application to know the location of the remote resource? Or have the application container actively perform the service discovery that the Ambassador Container was going to do? In this case, it's another waste of resources since we've inserted an extra "hop" in our network path to the remote resource and haven't reduced complexity in the system.
For this reason, Docker recommends using Overlay or Mesh Networks as an alternative.
Conclusion
Operationalizing applications are a critical part of developing microservice architectures. Applications have responsibilities to the platform, like logging, exception reporting, and providing metrics. Applications also rely on external services (and the platform) to provide essential services like discovery, configuration, and data storage.
Modern Docker environments go beyond single machine installations, employing schedulers that can manage extremely large clusters of hosts (with thousands of servers). We can no longer assume we know where our applications will live in the environment and we need to design our support services accordingly. One principle that helps this process is inverting the relationship between applications and supporting services. By making the application unaware of log infrastructure, metrics system, configuration, and monitoring we can choose the level of support between environments and make changes to infrastructure without affecting services. More importantly, our applications have fewer responsibilities, which reduces the potential for problems.
Finally, we discussed the patterns typically used in Docker environments for deploying and providing support to applications. While we can't completely remove the need for traditional integration mechanisms (remote services), for basic operation needs (logging, metrics, etc.) we can provide services accessible to containers on every host machine in our cluster. Some applications, however, need special support. For those use cases, we discussed the use of sidecar containers that are deployed alongside the primary application and don't need to be present on every host in an environment. We also talked about cutting edge integration techniques using Overlay and Mesh networks.
Thank you for your attention, especially if you read this post top-to-bottom. I realize this is an enormous topic, and I tried my best to pare the content down to only what was needed. If you have any questions on any of the points discussed in this article, please reach out to me on Twitter: @richardclayton.
Stumbling my way through the great wastelands of enterprise software development.
